22 KiB
Freqai
!!! Note Freqai is still experimental, and should be used at the user's own discretion.
Freqai is a module designed to automate a variety of tasks associated with training a predictive model to provide signals based on input features.
Among the the features included:
- Easy large feature set construction based on simple user input
- Sweep model training and backtesting to simulate consistent model retraining through time
- Smart outlier removal of data points from prediction sets using a Dissimilarity Index.
- Data dimensionality reduction with Principal Component Analysis
- Automatic file management for storage of models to be reused during live
- Smart and safe data standardization
- Cleaning of NaNs from the data set before training and prediction.
- Automated live retraining (still VERY experimental. Proceed with caution.)
General approach
The user provides FreqAI with a set of custom indicators (created inside the strategy the same way a typical Freqtrade strategy is created) as well as a target value (typically some price change into the future). FreqAI trains a model to predict the target value based on the input of custom indicators. FreqAI will train and save a new model for each pair in the config whitelist. Users employ FreqAI to backtest a strategy (emulate reality with retraining a model as new data is introduced) and run the model live to generate buy and sell signals.
Background and vocabulary
Features are the quantities with which a model is trained. X_i represents the
vector of all features for a single candle. In Freqai, the user
builds the features from anything they can construct in the strategy.
Labels are the target values with which the weights inside a model are trained toward. Each set of features is associated with a single label, which is also defined within the strategy by the user. These labels look forward into the future, and are not available to the model during dryrun/live/backtesting.
Training refers to the process of feeding individual feature sets into the model with associated labels with the goal of matching input feature sets to associated labels.
Train data is a subset of the historic data which is fed to the model during training to adjust weights. This data directly influences weight connections in the model.
Test data is a subset of the historic data which is used to evaluate the intermediate performance of the model during training. This data does not directly influence nodal weights within the model.
Install prerequisites
Use pip to install the prerequisites with:
pip install -r requirements-freqai.txt
Running from the example files
An example strategy, an example prediction model, and example config can all be found in
freqtrade/templates/ExampleFreqaiStrategy.py,
freqtrade/freqai/prediction_models/CatboostPredictionModel.py,
config_examples/config_freqai.example.json, respectively. Assuming the user has downloaded
the necessary data, Freqai can be executed from these templates with:
freqtrade backtesting --config config_examples/config_freqai.example.json --strategy FreqaiExampleStrategy --freqaimodel CatboostPredictionModel --strategy-path freqtrade/templates --timerange 20220101-20220201
Configuring the bot
Example config file
The user interface is isolated to the typical config file. A typical Freqai config setup includes:
"freqai": {
"startup_candles": 10000,
"timeframes" : ["5m","15m","4h"],
"train_period" : 30,
"backtest_period" : 7,
"identifier" : "unique-id",
"corr_pairlist": [
"ETH/USD",
"LINK/USD",
"BNB/USD"
],
"feature_parameters" : {
"period": 24,
"shift": 2,
"weight_factor": 0,
},
"data_split_parameters" : {
"test_size": 0.25,
"random_state": 42
},
"model_training_parameters" : {
"n_estimators": 100,
"random_state": 42,
"learning_rate": 0.02,
"task_type": "CPU",
},
}
Building the feature set
!! slightly out of date, please refer to templates/FreqaiExampleStrategy.py for updated method !!
Features are added by the user inside the populate_any_indicators() method of the strategy
by prepending indicators with %:
def populate_any_indicators(self, metadata, pair, df, tf, informative=None, coin=""):
informative['%-' + coin + "rsi"] = ta.RSI(informative, timeperiod=14)
informative['%-' + coin + "mfi"] = ta.MFI(informative, timeperiod=25)
informative['%-' + coin + "adx"] = ta.ADX(informative, window=20)
bollinger = qtpylib.bollinger_bands(qtpylib.typical_price(informative), window=14, stds=2.2)
informative[coin + "bb_lowerband"] = bollinger["lower"]
informative[coin + "bb_middleband"] = bollinger["mid"]
informative[coin + "bb_upperband"] = bollinger["upper"]
informative['%-' + coin + "bb_width"] = (
informative[coin + "bb_upperband"] - informative[coin + "bb_lowerband"]
) / informative[coin + "bb_middleband"]
# The following code automatically adds features according to the `shift` parameter passed
# in the config. Do not remove
indicators = [col for col in informative if col.startswith('%')]
for n in range(self.freqai_info["feature_parameters"]["shift"] + 1):
if n == 0:
continue
informative_shift = informative[indicators].shift(n)
informative_shift = informative_shift.add_suffix("_shift-" + str(n))
informative = pd.concat((informative, informative_shift), axis=1)
# The following code safely merges into the base timeframe.
# Do not remove.
df = merge_informative_pair(df, informative, self.config["timeframe"], tf, ffill=True)
skip_columns = [(s + "_" + tf) for s in ["date", "open", "high", "low", "close", "volume"]]
df = df.drop(columns=skip_columns)
The user of the present example does not want to pass the bb_lowerband as a feature to the model,
and has therefore not prepended it with %. The user does, however, wish to pass bb_width to the
model for training/prediction and has therfore prepended it with %._
Note: features must be defined in populate_any_indicators(). Making features in populate_indicators()
will fail in live/dry. If the user wishes to add generalized features that are not associated with
a specific pair or timeframe, they should use the following structure inside populate_any_indicators()
(as exemplified in freqtrade/templates/FreqaiExampleStrategy.py:
def populate_any_indicators(self, metadata, pair, df, tf, informative=None, coin=""):
# Add generalized indicators here (because in live, it will call only this function to populate
# indicators for retraining). Notice how we ensure not to add them multiple times by associating
# these generalized indicators to the basepair/timeframe
if pair == metadata['pair'] and tf == self.timeframe:
df['%-day_of_week'] = (df["date"].dt.dayofweek + 1) / 7
df['%-hour_of_day'] = (df['date'].dt.hour + 1) / 25
(Please see the example script located in freqtrade/templates/FreqaiExampleStrategy.py for a full example of populate_any_indicators())
The timeframes from the example config above are the timeframes of each populate_any_indicator()
included metric for inclusion in the feature set. In the present case, the user is asking for the
5m, 15m, and 4h timeframes of the rsi, mfi, roc, and bb_width to be included
in the feature set.
In addition, the user can ask for each of these features to be included from
informative pairs using the corr_pairlist. This means that the present feature
set will include all the base_features on all the timeframes for each of
ETH/USD, LINK/USD, and BNB/USD.
shift is another user controlled parameter which indicates the number of previous
candles to include in the present feature set. In other words, shift: 2, tells
Freqai to include the the past 2 candles for each of the features included
in the dataset.
In total, the number of features the present user has created is:_
no. timeframes * no. base_features * no. corr_pairlist * no. shift_
3 * 3 * 3 * 2 = 54._
Deciding the sliding training window and backtesting duration
Users define the backtesting timerange with the typical --timerange parameter in the user
configuration file. train_period is the duration of the sliding training window, while
backtest_period is the sliding backtesting window, both in number of days (backtest_period can be
a float to indicate sub daily retraining in live/dry mode). In the present example,
the user is asking Freqai to use a training period of 30 days and backtest the subsequent 7 days.
This means that if the user sets --timerange 20210501-20210701,
Freqai will train 8 separate models (because the full range comprises 8 weeks),
and then backtest the subsequent week associated with each of the 8 training
data set timerange months. Users can think of this as a "sliding window" which
emulates Freqai retraining itself once per week in live using the previous
month of data._
In live, the required training data is automatically computed and downloaded. However, in backtesting
the user must manually enter the required number of startup_candles in the config. This value
is used to increase the available data to FreqAI and should be sufficient to enable all indicators
to be NaN free at the beginning of the first training timerange. This boils down to identifying the
highest timeframe (4h in present example) and the longest indicator period (25 in present example)
and adding this to the train_period. The units need to be in the base candle time frame:_
startup_candles = ( 4 hours * 25 max period * 60 minutes/hour + 30 day train_period * 1440 minutes per day ) / 5 min (base time frame) = 1488.
!!! Note: in dry/live, this is all precomputed and handled automatically. Thus, startup_candle has no
influence on dry/live.
Running Freqai
Training and backtesting
The freqai training/backtesting module can be executed with the following command:
freqtrade backtesting --strategy FreqaiExampleStrategy --config config_freqai.example.json --freqaimodel CatboostPredictionModel --timerange 20210501-20210701
If this command has never been executed with the existing config file, then it will train a new model
for each pair, for each backtesting window within the bigger --timerange._
NOTE
Once the training is completed, the user can execute this again with the same config file and
FreqAI will find the trained models and load them instead of spending time training. This is useful
if the user wants to tweak (or even hyperopt) buy and sell criteria inside the strategy. IF the user
wants to retrain a new model with the same config file, then he/she should simply change the identifier.
This way, the user can return to using any model they wish by simply changing the identifier.
Building a freqai strategy
The Freqai strategy requires the user to include the following lines of code in the strategy:
from freqtrade.freqai.strategy_bridge import CustomModel
def informative_pairs(self):
whitelist_pairs = self.dp.current_whitelist()
corr_pairs = self.config["freqai"]["corr_pairlist"]
informative_pairs = []
for tf in self.config["freqai"]["timeframes"]:
for pair in whitelist_pairs:
informative_pairs.append((pair, tf))
for pair in corr_pairs:
if pair in whitelist_pairs:
continue # avoid duplication
informative_pairs.append((pair, tf))
return informative_pairs
def bot_start(self):
self.model = CustomModel(self.config)
def populate_indicators(self, dataframe: DataFrame, metadata: dict) -> DataFrame:
self.freqai_info = self.config['freqai']
# the following loops are necessary for building the features
# indicated by the user in the configuration file.
for tf in self.freqai_info['timeframes']:
for i in self.freqai_info['corr_pairlist']:
dataframe = self.populate_any_indicators(i,
dataframe.copy(), tf, coin=i.split("/")[0]+'-')
# the model will return 4 values, its prediction, an indication of whether or not the prediction
# should be accepted, the target mean/std values from the labels used during each training period.
(dataframe['prediction'], dataframe['do_predict'],
dataframe['target_mean'], dataframe['target_std']) = self.model.bridge.start(dataframe, metadata)
return dataframe
The user should also include populate_any_indicators() from templates/FreqaiExampleStrategy.py which builds
the feature set with a proper naming convention for the IFreqaiModel to use later.
Building an IFreqaiModel
Freqai has an example prediction model based on the popular Catboost regression (freqai/prediction_models/CatboostPredictionModel.py). However, users can customize and create
their own prediction models using the IFreqaiModel class. Users are encouraged to inherit train(), predict(),
and make_labels() to let them customize various aspects of their training procedures.
Running the model live
Freqai can be run dry/live using the following command
freqtrade trade --strategy FreqaiExampleStrategy --config config_freqai.example.json --freqaimodel ExamplePredictionModel
By default, Freqai will not find find any existing models and will start by training a new one
given the user configuration settings. Following training, it will use that model to predict for the
duration of backtest_period. After a full backtest_period has elapsed, Freqai will auto retrain
a new model, and begin making predictions with the updated model. FreqAI backtesting and live both
permit the user to use fractional days (i.e. 0.1) in the backtest_period, which enables more frequent
retraining. But the user should be careful that using a fractional backtest_period with a large
--timerange in backtesting will result in a huge amount of required trainings/models.
If the user wishes to start dry/live from a backtested saved model, the user only needs to reuse
the same identifier parameter
"freqai": {
"identifier": "example",
}
In this case, although Freqai will initiate with a
pre-trained model, it will still check to see how much time has elapsed since the model was trained,
and if a full backtest_period has elapsed since the end of the loaded model, FreqAI will self retrain.
Data anylsis techniques
Controlling the model learning process
The user can define model settings for the data split data_split_parameters and learning parameters
model_training_parameters. Users are encouraged to visit the Catboost documentation
for more information on how to select these values. n_estimators increases the
computational effort and the fit to the training data. If a user has a GPU
installed in their system, they may benefit from changing task_type to GPU.
The weight_factor allows the user to weight more recent data more strongly
than past data via an exponential function:
W_i = \exp(\frac{-i}{\alpha*n}) where W_i is the weight of data point i in a total set of n data points._
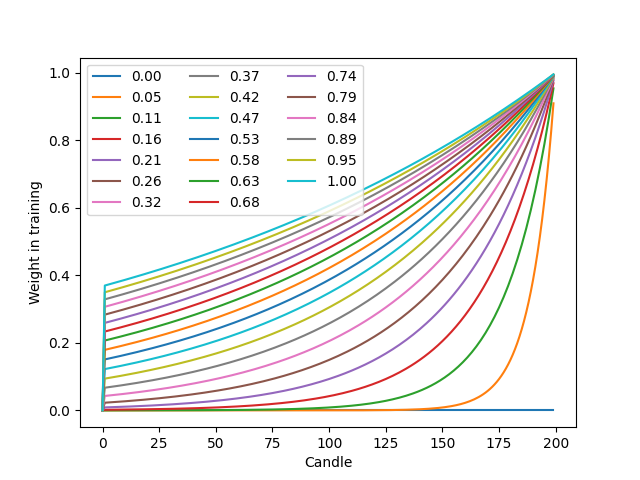
Finally, period defines the offset used for the labels. In the present example,
the user is asking for labels that are 24 candles in the future.
Removing outliers with the Dissimilarity Index
The Dissimilarity Index (DI) aims to quantify the uncertainty associated with each prediction by the model. To do so, Freqai measures the distance between each training data point and all other training data points:
d_{ab} = \sqrt{\sum_{j=1}^p(X_{a,j}-X_{b,j})^2} where d_{ab} is the distance between the normalized points a and b. $p$
is the number of features i.e. the length of the vector X. The
characteristic distance, \overline{d} for a set of training data points is simply the mean
of the average distances:
\overline{d} = \sum_{a=1}^n(\sum_{b=1}^n(d_{ab}/n)/n) \overline{d} quantifies the spread of the training data, which is compared to
the distance between the new prediction feature vectors, X_k and all the training
data:
d_k = \argmin_i d_{k,i} which enables the estimation of a Dissimilarity Index:
DI_k = d_k/\overline{d} Equity and crypto markets suffer from a high level of non-patterned noise in the form of outlier data points. The dissimilarity index allows predictions which are outliers and not existent in the model feature space, to be thrown out due to low levels of certainty. Activating the Dissimilarity Index can be achieved with:
"freqai": {
"feature_parameters" : {
"DI_threshold": 1
}
}
The user can tweak the DI with DI_threshold to increase or decrease the extrapolation of the
trained model.
Reducing data dimensionality with Principal Component Analysis
Users can reduce the dimensionality of their features by activating the principal_component_analysis:
"freqai": {
"feature_parameters" : {
"principal_component_analysis": true
}
}
Which will perform PCA on the features and reduce the dimensionality of the data so that the explained variance of the data set is >= 0.999.
Removing outliers using a Support Vector Machine (SVM)
The user can tell Freqai to remove outlier data points from the training/test data sets by setting:
"freqai": {
"feature_parameters" : {
"use_SVM_to_remove_outliers: true
}
}
Freqai will train an SVM on the training data (or components if the user activated
principal_component_analysis) and remove any data point that it deems to be sit beyond the
feature space.
Stratifying the data
The user can stratify the training/testing data using:
"freqai": {
"feature_parameters" : {
"stratify": 3
}
}
which will split the data chronologically so that every Xth data points is a testing data point. In the present example, the user is asking for every third data point in the dataframe to be used for testing, the other points are used for training.
Setting up a follower
The user can define:
"freqai": {
"follow_mode": true,
"identifier": "example"
}
to indicate to the bot that it should not train models, but instead should look for models trained
by a leader with the same identifier. In this example, the user has a leader bot with the
identifier: "example" already running or launching simultaneously as the present follower.
The follower will load models created by the leader and inference them to obtain predictions.
Purging old model data
FreqAI stores new model files each time it retrains. These files become obsolete as new models
are trained and FreqAI adapts to the new market conditions. Users planning to leave FreqAI running
for extended periods of time with high frequency retraining should set purge_old_models in their
config:
"freqai": {
"purge_old_models": true,
}
which will automatically purge all models older than the two most recently trained ones.
Additional information
Feature normalization
The feature set created by the user is automatically normalized to the training data only. This includes all test data and unseen prediction data (dry/live/backtest).
File structure
user_data_dir/models/ contains all the data associated with the trainings and
backtests. This file structure is heavily controlled and read by the FreqaiDataKitchen()
and should thus not be modified.